This will be the first post in a series of blog posts where I’ll try to cover some of the fundamental ideas behind some basic reinforcement learning algorithms. Throughout this series, I will refer to some of the intuition behind certain key elements incorporated into these algorithms and provide some simple python implementations tested on OpenAI’s gym package. I will start by covering tabular methods for RL and in later posts move onto algorithms that use neural networks for function approximation. Most of the information found in this series can be obtained by reading Andrew Barto and Richard S. Sutton’s excellent Introduction to Reinforcement Learning textbook, which is freely available to all. Personally, I’ve watched most of the lectures from David Silver’s RL UCL course and worked a couple exercises found in the Pratical_RL GitHub course and Denny Britz’s RL repository. Occasionally, I may refer to other resources, which I will be sure to note down when necessary. All the code used in this blog plot post is freely available on my Github.
I assume that readers of this blog have taken a basic statistics course and have a high-level understanding of reinforcement learning (i.e. know the definitions of a reward, normal distribution, Markov Decision Process, etc). If not, I may go over some of these topics in another blog post. However, I imagine the ideal reader for this blog series is somewhat like me when I first encountered reinforcement learning. That is, a wide-eyed undergraduate student with a basic understanding of formal mathematics/statistics, some decent software engineering experience and a lot of extra time on their hands.
So on to the topic at hand, Monte Carlo learning is one of the fundamental ideas behind reinforcement learning. This method depends on sampling states, actions and rewards from a given environment. This means that one does not need to know the entire probability distribution associated with each state transition or have a complete model of the environment. Instead, as long as there exists a method to sample from the enviroment, one can use any captured experience data to learn an optimal policy over a large number of episodes. Furthermore, a policy, in the RL sense, is a way of picking actions at every state ( 
Generalized Policy Iteration

So how does this all work? Well, like more traditional dynamic programming methods for control, Monte Carlo algorithms follow the Generalized Policy Iteration (GPI) framework. This framework can be broken down into two steps; policy evaluation and policy improvement. The policy evaluation step involves iterating on Q-value estimates or state-action values based on new data obtained from completing an episode. These Q-values give a numerical value for being in a given state and taking a particular action, 





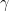
Once policy evaluation is complete the second step of GPI is the policy improvement step. This step involves improving upon the current policy (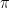


On-policy,  -greedy, First-visit Monte Carlo
-greedy, First-visit Monte Carlo
The first actual example of a Monte Carlo algorithm that we’ll look at is the on-policy, 

The on-policy part of this algorithm addresses how this algorithm uses the same policy for state-space exploration and policy improvement. This means that the generated Q-values would only ever correspond to a near-optimal policy with some exploration. The alternative approach would be to use two policies where one would be used for exploration and the other for policy improvement. This type of algorithm is known as an off-policy method and will be described in the next section.
Finally, the first-visit aspect of this algorithm refers to how this algorithm only looks at the first time any given state,
An implementation of the discussed algorithm in python is provided below with a line-by-line explanation following:
def mc_control_epsilon_greedy(env, num_episodes, discount_factor=1.0, epsilon=0.1):
"""
Monte Carlo Control using Epsilon-Greedy policies.
Finds an optimal epsilon-greedy policy.
Args:
env: OpenAI gym environment.
num_episodes: Number of episodes to sample.
discount_factor: Gamma discount factor.
epsilon: Chance the sample a random action. Float betwen 0 and 1.
Returns:
A tuple (Q, policy).
Q is a dictionary mapping state to action values.
policy is a function that takes an observation as an argument and returns
action probabilities
"""
# Keeps track of sum and count of returns for each state
# to calculate an average. We could use an array to save all
# returns (like in the book) but that's memory inefficient.
returns_sum = defaultdict(float)
returns_count = defaultdict(float)
# The final action-value function.
# A nested dictionary that maps state to (action to action-value).
Q = defaultdict(lambda: np.zeros(env.action_space.n))
# A nested dictionary that maps state to (action to number of times state-action pair was encountered).
N = defaultdict(lambda: np.zeros(env.action_space.n))
iterations = 0
# policy improvement: this function holds a reference to the Q_values
policy = make_epsilon_greedy_policy(Q, epsilon, env.action_space.n)
while iterations < num_episodes:
done = False
episode = []
visited_states = {}
s = env.reset()
while not done:
# choose an action based on a probability dist generated by policy(), epsilon/ |A(s)| chance of random action
action = np.random.choice(range(env.action_space.n), p=policy(s))
new_s, r, done, _ = env.step(action)
episode.append((s, action, r))
for state,action,reward in episode[::-1]:
# first-visit monte carlo update
if state not in visited_states:
N[state][action] += 1
# incremental update of Q value is more memory efficient than simply keeping a record of all rewards
# and averaging after every new reward
Q[state][action] += discount_factor * ( 1./ N[state][action] ) * (reward - Q[state][action])
visited_states.add(state)
iterations += 1
return Q, policy
Line 32: make_epsilon_greedy_policy() just returns a function that takes an epsilon greedy approach to selecting actions within a given state.
Lines 38 – 42: Here I sample the environment (exploration) by selecting actions based on the policy function and record each of the state-action-reward tuples for the exploitation step later.
Lines 43- 49: Here is where the bulk of the logic associated with this algorithm lies. First thing to note here is that I iterate through the episode backwards. This is required to properly apply discounting when computing the Q value updates (i.e. rewards appearing early in the episode are discounted less than later rewards). If you have have trouble understanding the update rule in line 49, I recommend relating the equation to 
Line 50: Finally, I store each of the encountered states within an episode in the visited set to enforce the first-visit nature of this algorithm.
Off-policy Monte Carlo with Weighted Importance Sampling
The next algorithm of importance is the off-policy Monte Carlo method with weighted importance sampling. The off-policy nature of this algorithm refers to how this algorithm relies on two separate policies; the behavior policy ( 
Off-policy Monte Carlo algorithms also rely on a simple statistical technique known as importance sampling. This technique involves estimating expected values of one distribution given samples from another. Using this technique, it is easy to use episodes from policy
Subsequently, with this requirement met, one can define the importance sampling ratio. This ratio defines the relative probability of a specific state-action trajectory occurring under the target and behavior policies. This ratio can then be used to weigh all of the returns obtained from following policy 



Given the importance sampling ratio, there are two ways of estimating the expected return for off-policy Monte Carlo methods. The first method is known as ordinary importance sampling and is given by the following definition, 






An implementation of this algorithm in python is provided below:
def mc_control_importance_sampling(env, num_episodes, behavior_policy, discount_factor=1.0):
"""
Monte Carlo Control Off-Policy Control using Weighted Importance Sampling.
Finds an optimal greedy policy.
Args:
env: OpenAI gym environment.
num_episodes: Number of episodes to sample.
behavior_policy: The behavior to follow while generating episodes.
A function that given an observation returns a vector of probabilities for each action.
discount_factor: Gamma discount factor.
Returns:
A tuple (Q, policy).
Q is a dictionary mapping state to action values.
policy is a function that takes an observation as an argument and returns
action probabilities. This is the optimal greedy policy.
"""
# A dictionary that maps state to action values
Q = defaultdict(lambda: np.zeros(env.action_space.n))
# A dictionary that maps state to product of importance sampling ratios
C = defaultdict(lambda: np.zeros(env.action_space.n))
states = []
start = []
# purely greedy policy on Q values
target_policy = create_greedy_policy(Q)
iterations = 0
while iterations < num_episodes:
episode = []
s = env.reset()
done = False
# generate episode data using behaviour policy
while not done:
action = np.random.choice(range(env.action_space.n), p=behavior_policy(s))
new_s, r, done, _ = env.step(action)
episode.append((s,action,r))
s = new_s
G = 0.0
W = 1.0
# iterate through the episode, backwards to propagate final reward
for state,action,reward in episode[::-1]:
G = discount_factor * G + reward
C[state][action] += W
# policy evaluation and policy improvement steps occur simultaneously here
# as create_greedy_policy holds a reference to Q
Q[state][action] += (W / C[state][action]) * (G - Q[state][action])
# don't update W for an action that wouldn't have been selected by π
if action != np.random.choice(range(env.action_space.n), p=target_policy(state)):
break
# using a deterministic policy for target policy so π(a|s) is always 1
W = W * (1. / behavior_policy(state)[action])
iterations += 1
return Q, target_policy
Line 27: Create a general argmax based deterministic policy function for the target policy.
Lines 31 – 38: Generate an episode of experience by interacting with the environment.
Line 42 – 43: Calculate the expected reward by iterating backwards through the episode and discounting future rewards appropriately.
Line 44: Maintain a sum of the importance sampling ratios up to the current step.
Line 47: Perform the main step of policy improvement by updating the Q value for the given state-action tuple along with the weighted importance sampling ratio.
Lines 49 – 50: Stop policy improvement if the behavioral policy makes an action contrary to the target policy. This early break reduces the amount of exploration that the policy update step will tolerate from the actions taken by the behavior policy. In practice, it is best to select a behavioral policy closer to the optimal target policy for better convergence properties.
Line 52: Update importance sampling ratio for the next step of policy update.
Monte Carlo and Beyond
There are many forms of Monte Carlo methods that aren’t covered in this blog post (i.e. Monte Carlo Tree Search). Nevertheless, the two mentioned in this post remain some of the most fundamental for reinforcement learning. Nevertheless, Monte Carlo methods are very restrictive in that they require episodes to terminate as Q-values can only be updated at the very end. This restriction is lifted with temporal difference (TD) learning. This idea will be the topic of the next blog post along with implementations of some popular versions of the Q-learning.

Hello?
It seems this blog is too long ago, but I hope you can see this.
I have read through your blog, and interested in your code. However, I first thought that discount factor and return in your code is a method, but it is not. So how could you sum the return? and the discount factor and to decrease exponentially. Am I missing something?
LikeLiked by 1 person
Hi Satrakol, thanks for visiting my blog! I don’t think I ever mention that I exponentially decay the discount factor rather I use the discount factor to exponentially decay the value of future rewards. Notice when I’m updating the Q values in the policy improvement step, I iterate through the episode backwards and use the discount factor to exponentially decrease the significance of older rewards. You may be confusing the discount factor with epsilon, which is more common expoentially decreased to tune the exploration-exploitation behaviour during training for Q-learning.
LikeLike